GlusterFS est un système de fichiers réseau client/serveur permettant d’agréger différents nœuds de stockage afin de fournir un environnement NAS hautement disponible.
1. Présentation
1.1 Pour quoi faire ?
Admettons que j’ai une application Web lambda, je vais pouvoir déployer plusieurs instances Apache ou Nginx qui se trouveront derrière un équilibreur de charge, lui-même hautement disponible. Sur chaque instance de serveur Web, il me sera facile de déployer l’application. Toutefois chaque instance aura besoin d’accéder à des fichiers communs, générés ou non par l’application. Bien souvent, je vais rencontrer dans ce cas un serveur NFS qui va donc lui-même constituer un point de faiblesse dans l’architecture.
Gluster permet de mettre en cluster plusieurs nœuds de stockage (à minima deux), ce qui permet de répondre à deux problématiques majeures dès qu’une application a besoin de pouvoir monter en charge : la parallélisation et la réplication du stockage. Pour fournir ces fonctionnalités sur un volume, une « brick » en langage Gluster, le système s’appuie sur des systèmes de fichiers traditionnels, XFS ou EXT4 au-dessus d’un périphérique en mode bloc (partition, LVM, RAID, etc..). Gluster travaille donc principalement au niveau fichier.
Contrairement à un certain nombre d’autres systèmes de fichiers de ce type, Gluster offre l’immense avantage de ne pas nécessiter de serveur de méta données pour fonctionner. De fait, cette absence ne constitue pas un point de faiblesse ou un élément supplémentaire à maintenir dans l’infrastructure de stockage. De plus, chaque fois que l’on ajoute un nœud au cluster, le système devient plus performant et l’augmentation de la performance est linéaire avec l’extension de l’infrastructure. Dernier point pour mettre en évidence cette simplicité de conception, il n’existe pas de notion de maître ou d’esclave avec GlusterFS.
1.2 Les volumes GlusterFS
Un volume est une agrégation de plusieurs bricks répartis sur différents nœuds de stockage. Le choix du type de volume se fait en fonction des attentes de performances, de sécurité ou de la combinaison des deux. Voyons les types de volumes standards, sachant qu’il existe des modes géo-répliqués, strippés ou basés sur l’erasure coding pour des workflows spécifiques.
1.2.1 Volume distribué
Ce mode est le mode par défaut de GlusterFS. Les fichiers sont répartis sur l’ensemble des bricks du volume sans redondance aucune. Par conséquent, lors de la perte d’un nœud, les données de celui-ci sont perdues et il faudra se baser sur des mécanismes complémentaires pour assurer la reprise après incident. La volumétrie utile est celle de l’ensemble des nœuds du cluster Ce mode permet une croissance aisée de la volumétrie en ajoutant simplement des nœuds au volume. Il faut donc au minimum deux nœuds, et la distribution peut se faire sur autant de nœuds du cluster (voir figure 1).
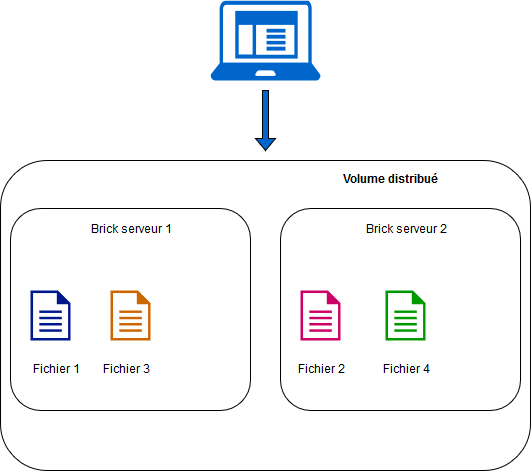
Fig. 1: Volume distribué.
1.2.2 Volume répliqué
Ce mode permet de répondre au problème de la sécurité de la donnée posé par le mode distribué. Dans ce mode opératoire, le système maintient n copies de chaque fichier au sein des « bricks » spécifiées. Il faut donc autant de nœuds au cluster que de réplicas désirés. De la même façon que sur du RAID1, la volumétrie utile est la moitié de la volumétrie allouée (voir figure 2).
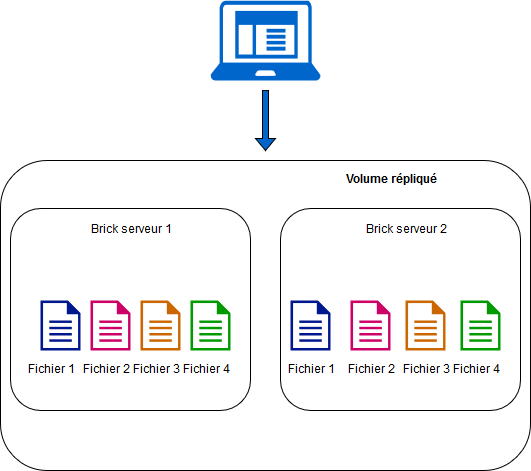
Fig. 2: Volume répliqué.
1.2.3 Volume distribué répliqué
Vous l’aurez compris, ce mode est une combinaison des deux modes précédents. Cela permet de traiter des workflows nécessitant disponibilité et capacité à monter en charge. Le nombre de bricks nécessaires est un multiple du niveau de réplication attendu. De plus, la réplication entre les bricks est définie par leur ordre de déclaration à la création du volume. Pour quatre bricks avec deux réplicas, les deux premières bricks répliquent ensemble et de même pour les deux suivantes (voir figure 3). Si nous souhaitions quatre réplicas, il nous faudrait donc huit bricks et les quatre premières répliqueraient entre elles.
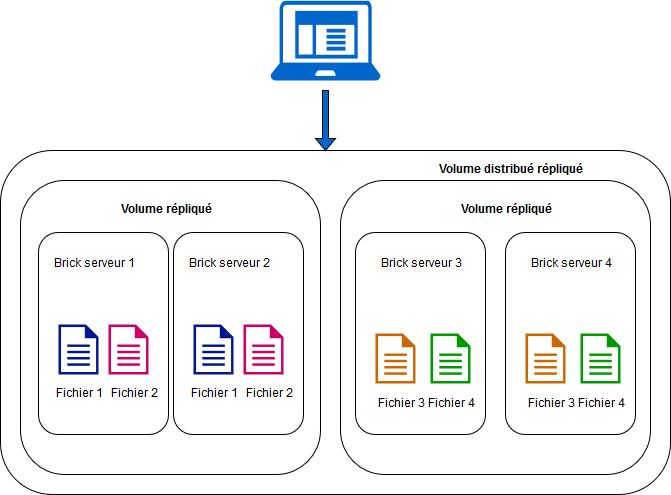
Fig. 3: Volume distribué répliqué.
2 Un peu de pratique
2.1 L’environnement
GlusterFS est assez agnostique par rapport à l’environnement et à la distribution. Pour ma part, les démonstrations suivantes seront toutes réalisées sous Ubuntu 16.04. Un point indispensable étant que les nœuds soient capables de discuter par leur nom, qu’il soit résolu par DNS ou par le fichier hosts, mais pas par adresse IP. Pour la suite, je partirai sur deux VMs stor0 et stor1 afin de monter un cluster à deux nœuds.
Chaque serveur dispose d’un second disque virtuel de 10 Gio pour la démonstration. Le périphérique doit par contre impérativement disposer d’un système de fichiers supportant les attributs étendus, ext4 ou XFS sachant qu’XFS est de loin le système de fichiers recommandé. La convention de nommage veut, mais n’impose pas, que les données soient placées dans /data/glusterfs/volume/brick. La création des volumes peut se faire simplement comme ceci :
$ apt-get -y install lvm2 acl attr xfsprogs $(echo o; echo n; echo p; echo 1; echo ; echo; echo t; echo 8E; echo w) | fdisk /dev/sdb $ pvcreate /dev/sdb1 $ vgcreate VG-Brick0 /dev/sdb1 $ lvcreate -l 100%VG -n LV-Brick0 VG-Brick0 $ mkfs.xfs -i size=512 -L Brick0 /dev/VG-Brick0/LV-Brick0 $ mkdir -p /data/glusterfs/vol0/ $ echo "/dev/VG-Brick0/LV-Brick0 /data/glusterfs/vol0/ xfs defaults 1 2" >> /etc/fstab $ mount /data/glusterfs/vol0/ $ mkdir /data/glusterfs/vol0/brick0
Le LVM n’est pas obligatoire, mais s’y tenir permet d’avoir les bons réflexes pour de la production. Pour le reste, l’installation des packages est très simple, cette simple commande suffit :
$ apt-get -y install glusterfs-server
Par souci de simplification, aucun pare-feu n’est activé sur les différentes machines. Point de vigilance, il ne faudra pas cloner les machines avec le disque de données supplémentaire.
2.2 Le trusted pool
Avant d’être en mesure de gérer des volumes de stockage, les membres d’un cluster GlusterFS doivent se reconnaître entre eux et faire partie d’un même trusted pool. Tant que cette opération n’est pas réalisée, il n’est pas possible pour un hôte de joindre le réseau de stockage. Pour cela, c’est très simple, il suffit depuis un nœud de sonder avec la commande gluster peer probe d’ajouter les autres nœuds :
root@stor1:~# gluster peer probe stor0 peer probe: success.
Pour vérifier :
root@stor1:~# gluster peer status Number of Peers: 1 Hostname: stor0 Uuid: a920b020-9e5a-46f6-b073-1cc8ec00ba0e State: Peer in Cluster (Connected)
2.3 Un volume répliqué
On va poursuivre notre itinéraire au sein de GlusterFS en créant un volume répliqué à deux nœuds. J’ai donné en introduction un exemple basé sur des attentes de haute disponibilité du stockage, il me semble pertinent de poursuivre sur cet exemple qui parlera sans doute davantage. Notre cluster ayant deux nœuds, avec conservation de deux copies, cela nous fait donc un système en miroir. Sur chaque serveur, on indique le dossier dans lequel se trouvent les données. Par sécurité, il est préconisé de créer le volume dans un sous-répertoire du point de montage afin qu’en cas d’échec de montage du volume, cela n’ait pas d’incidence sur la réplication gluster. Du fait du risque d’avoir un dossier vide sur un membre du cluster lors du démarrage des services, le comportement ne serait pas forcément prévisible.
root@stor1:~# gluster volume create repl-vol replica 2 transport tcp stor0:/data/glusterfs/vol0/brick0/ stor1:/data/glusterfs/vol0/brick0/ volume create: repl-vol: success: please start the volume to access data root@stor1:~# gluster volume start repl-vol volume start: repl-vol: success
On peut donc vérifier que tout est en ordre avec la commande ci-dessous. Le volume doit être marqué comme online sur l’ensemble des nœuds :
root@stor1:~# gluster volume status Status of volume: repl-vol Gluster process TCP Port RDMA Port Online Pid ------------------------------------------------------------------------------ Brick stor0:/data/glusterfs/vol0/brick0 49152 0 Y 2536 Brick stor1:/data/glusterfs/vol0/brick0 49152 0 Y 2338 NFS Server on localhost 2049 0 Y 2359 Self-heal Daemon on localhost N/A N/A Y 2364 NFS Server on stor0 2049 0 Y 2557 Self-heal Daemon on stor0 N/A N/A Y 2562 Task Status of Volume repl-vol ------------------------------------------------------------------------------ There are no active volume tasks
2.4 Connexion d’un client
Il existe trois mécanismes d’accès principaux côté client :
– le client natif accédé au travers de FUSE, le système permettant de créer des pilotes de filesystem au niveau userland. Il suffit pour cela d’installer les packages nécessaires.
– via NFS, Gluster impémentant nativement le support NFS. Si vous avez été vigilant lors de l’installation du package glusterfs-server, vous avez sûrement remarqué certaines dépendances. Le serveur NFS n’est pas activé par défaut cependant.
– en CIFS, avec un serveur Samba.
Dans les deux derniers cas, il est souhaitable d’associer les serveurs à un système de type CTDB pour fournir de la haute disponibilité. NFS et Samba ne savent en effet pas tirer parti de l’ensemble des fonctionnalités contrairement au client natif. Connectons donc un premier client :
$ apt-get -y install glusterfs-client $ mkdir /data $ mount -t glusterfs stor1:/repl-vol /data
Créons un fichier aléatoire avec par exemple la commande ci-dessous.
$ dd if=/dev/urandom of=/data/toto bs=1024 count=10240
Pour confirmer que la réplication est fonctionnelle, il suffit de vérifier avec une simple commande ls que le fichier est présent sur les bricks de chacun des deux serveurs GlusterFS :
$ ls -l /data/glusterfs/vol0/brick0/toto -rw-r--r-- 2 root root 10485760 sept. 9 19:58 /data/glusterfs/vol0/brick0/toto
Un point qui a dû vous surprendre est la commande de montage. On a en effet explicitement spécifié l’un des serveurs alors que l’on est censé avoir déployé un stockage hautement disponible. En pratique, le client natif glusterfs ne fait que récupérer lors de la commande de mount les informations de configuration du cluster. Il communiquera directement avec l’ensemble des serveurs définis dans les volfile (dans le répertoire /var/lib/glusterd/vols/repl-vol sur les nœuds de stockage). Un bon moyen de vérifier est d’arrêter le nœud vers lequel on a réalisé le montage (un halt -p sur stor1 dans ce cas) : le client doit continuer à fonctionner. Côté client, la perte de connexion doit être visible dans le fichier /var/log/glusterfs/data.log
[2017-09-09 18:01:18.933835] W [socket.c:588:__socket_rwv] 0-glusterfs: readv on 192.168.69.61:24007 failed (Aucune donnée disponible) [2017-09-09 18:01:37.954070] W [socket.c:588:__socket_rwv] 0-repl-vol-client-1: readv on 192.168.69.61:49152 failed (Connexion terminée par expiration du délai d'attente)
Un point que vous aurez noté également, c’est que la bascule n’est pas immédiate. En pratique, le délai est de 42 secondes. Pour ramener ce délai à une valeur plus raisonnable de 5 secondes, modifions notre nœud comme suit :
root@stor1:~# gluster volume set repl-vol network.ping-timeout 5 volume set: success
Ce changement est tracé dans le log /var/log/glusterfs/glustershd.log avec une ligne par nœud comme celle-ci :
[2017-09-09 18:33:19.591108] I [rpc-clnt.c:1823:rpc_clnt_reconfig] 0-repl-vol-client-0: changing ping timeout to 5 (from 42)
2.5 Un brin de sécurité
Jusqu’ici, on a pu monter le volume simplement en contactant l’un des serveurs du pool GlusterFS, mais aucune sécurité supplémentaire n’a été imposée. Il est possible de restreindre l’accès à notre volume en définissant une ACL similaire à ce qui existe en NFS via le fichier /etc/exports.
root@stor2:~# gluster volume set repl-vol auth.allow 192.168.69.104 volume set: success
Il est également possible de définir une wildcard, par exemple 192.168.69.* afin d’autoriser tout un réseau. Dans cet exemple, nous avons autorisé explicitement une adresse IP à se connecter au volume.
Nous aurions également pu autoriser un nom d’hôte ou plusieurs adresses IP ou noms séparés par des virgules. Le fait de définir l’attribut auth.allow a comme effet immédiat d’interdire toutes les autres machines qui n’ont pas été explicitement autorisées. Pour revenir au comportement par défaut, il faut autoriser le caractère wildcard (*) tout simplement. A l’inverse, l’attribut auth.reject n’interdit aucune machine par défaut (auth.reject avec comme valeur NONE). Il sert comme vous l’avez deviné à interdire explicitement une machine. Pour résumer, le contrôle d’accès a une logique similaire avec ce qui existe côté TCP Wrappers.
2.6 Une corbeille sur le volume
GlusterFS sait gérer une corbeille au niveau volume pour conserver les fichiers supprimés. Le dossier est créé automatiquement par gluster et ne peut être supprimé. Fait intéressant, gluster sait si on le lui dit, tirer parti de cette corbeille pour ses opérations internes. Activons donc une corbeille pour les fichiers de moins de 10 Mio :
$ gluster volume set repl-vol features.trash on $ gluster volume set repl-vol features.trash-dir "Corbeille" $ gluster volume set repl-vol features.trash-max-filesize 10485760 $ gluster volume set repl-vol features.trash-internal-op on
2.7 Node HS ? Pas de panique !
Un incident majeur sur un équipement sensible d’un système d’information, c’est bien entendu quelque chose auquel on se doit d’être préparé. Dans un système hautement disponible, tout élément qui n’est pas considéré comme un point unique de défaillance (SPOF) doit pouvoir être indisponible sans impacter fortement le bon fonctionnement du système. Nous nous retrouvons dans un état de fonctionnement dégradé. Si le système défaillant ne peut être dépanné, un processus de reconstruction doit être mis en œuvre.
Nous allons considérer que le nœud stor0 est irrémédiablement défaillant, la VM est même supprimée. Cela se vérifie par la commande suivante :
root@stor1:~# gluster volume heal repl-vol info Brick stor0:/data/glusterfs/vol0/brick0 Status: Noeud final de transport n'est pas connecté Brick stor1:/data/glusterfs/vol0/brick0 Number of entries: 0
Voyons étape par étape comment le nouveau serveur nommé stor2 va prendre de relais de celui-ci. Pour cela, la première étape que je ne vais pas détailler consiste à provisionner un nouveau serveur avec le disque de données et les dépendances comme indiqué précédemment.
Premièrement, on ajoute le nouveau nœud et on va confirmer qu’on a bien un nouveau nœud présent, et un ancien toujours connu du cluster mais manquant :
root@stor1:~# gluster peer probe stor2 peer probe: success. root@stor1:~# gluster peer status Number of Peers: 2 Hostname: stor0 Uuid: a920b020-9e5a-46f6-b073-1cc8ec00ba0e State: Peer in Cluster (Disconnected) Hostname: stor2 Uuid: f2a03465-11bb-4c2a-a882-22933cfa2d08 State: Peer in Cluster (Connected)
Remplaçons maintenant la brick du stor0 par celle de notre nouveau serveur stor2 et vérifions son état de santé :
root@stor1:~# gluster volume replace-brick repl-vol stor0:/data/glusterfs/vol0/brick0 stor2:/data/glusterfs/vol0/brick0 commit force volume replace-brick: success: replace-brick commit force operation successful
On réconcilie le volume :
root@stor1:~# gluster volume heal repl-vol full Launching heal operation to perform full self heal on volume repl-vol has been successful Use heal info commands to check status root@stor1:~# gluster volume heal repl-vol info Brick stor2:/data/glusterfs/vol0/brick0 Number of entries: 0 Brick stor1:/data/glusterfs/vol0/brick0 Number of entries: 0
Et depuis le nouveau node, lançons une synchronisation :
root@stor2:/data/glusterfs/vol0/brick0# gluster volume sync stor1 repl-vol Sync volume may make data inaccessible while the sync is in progress. Do you want to continue? (y/n) y
Il nous reste une dernière étape : répliquer le volume id dans les attributs étendus du système de fichiers et le propager au second serveur. Pour le récupérer, il faut lancer la commande suivante :
root@stor1:~# getfattr -n trusted.glusterfs.volume-id /data/glusterfs/vol0/brick0/ getfattr: Suppression des « / » en tête des chemins absolus # file: data/glusterfs/vol0/brick0/ trusted.glusterfs.volume-id=0seEhN1zXZTFOXmRGV92ibvw==
Sur le nouveau serveur, on applique l’ID du volume sur la brick :
root@stor2:/data/glusterfs/vol0/brick0# setfattr -n trusted.glusterfs.volume-id -v '0seEhN1zXZTFOXmRGV92ibvw==' /data/glusterfs/vol0/brick0/ service glusterfs-server restart
La configuration de notre volume est bien mise à jour comme on peut le voir ci-dessous. Dans le cadre d’un volume distribué, il faudrait lancer un rééquilibrage (rebalance) du volume :
root@stor1:~# gluster volume info repl-vol Volume Name: repl-vol Type: Replicate Volume ID: 1c493043-9c2d-4be6-afcd-8512577342c9 Status: Started Number of Bricks: 1 x 2 = 2 Transport-type: tcp Bricks: Brick1: stor2:/data/glusterfs/vol0/brick0 Brick2: stor1:/data/glusterfs/vol0/brick0 Options Reconfigured: performance.readdir-ahead: on cluster.self-heal-daemon: enable network.ping-timeout: 5
Enfin, il ne reste plus qu’à retirer l’ancien nœud des peers autorisés dans le trusted pool :
root@stor1:~# gluster peer detach stor0 peer detach: success root@stor1:~# gluster peer status Number of Peers: 1 Hostname: stor2 Uuid: f2a03465-11bb-4c2a-a882-22933cfa2d08 State: Peer in Cluster (Connected)
Il ne doit plus apparaître dans la liste des nœuds :
root@stor1:~# gluster pool list UUID Hostname State 0cb0f3b6-10e5-41c4-ad7e-cb9ca794db9e stor2 Connected d5ff9617-6989-48ae-be3a-3e1286060ea1 localhost Connected
Vous savez désormais comment remplacer un nœud défaillant, sachant que ce processus s’applique également en cas de migration de la brick de stor0 vers un nouveau serveur.
2.8 Étendre le volume
Quand l’espace disque commence à manquer, une première solution peut être d’étendre l’espace libre sur les bricks, d’où l’intérêt d’être partis au départ sur du LVM. Une autre solution est d’étendre le cluster avec de nouveaux nœuds afin d’améliorer la disponibilité du système dans son ensemble. Cette extension du cluster se fait en outre sans interruption de service.
Pour étendre un cluster répliqué, il faut ajouter un nombre de bricks avec un nombre multiple du nombre de réplicas. Nous avons monté un volume à deux réplicas, il nous faut donc ajouter deux bricks supplémentaires. La commande gluster volume info repl-vol nous permet de le confirmer (1×2). Nous allons ajouter donc deux serveurs stor3 et stor4, avec le volume disque préparé et le package glusterfs-server installé.
La première étape consiste à autoriser les deux nœuds avec la commande gluster peer probe vue précédemment. On peut donc ensuite ajouter des bricks au volume en spécifiant les bricks de nos deux nouveaux serveurs :
root@stor2:~# gluster volume add-brick repl-vol stor3:/data/glusterfs/vol0/brick0 stor4:/data/glusterfs/vol0/brick0 volume add-brick: success
Vérifions notre volume, nous devons retrouver nos deux bricks supplémentaires.
root@stor2:~# gluster volume info repl-vol Volume Name: repl-vol Type: Distributed-Replicate Volume ID: 78484dd7-35d9-4c53-9799-1195f7689bbf Status: Started Number of Bricks: 2 x 2 = 4 Transport-type: tcp Bricks: Brick1: stor2:/data/glusterfs/vol0/brick0 Brick2: stor1:/data/glusterfs/vol0/brick0 Brick3: stor3:/data/glusterfs/vol0/brick0 Brick4: stor4:/data/glusterfs/vol0/brick0 Options Reconfigured: performance.readdir-ahead: on
Notre volume à deux réplicas comportant quatre nœuds se comporte donc désormais comme un volume distribué répliqué par la magie de l’extension du volume. Seul problème, il n’y a aucune donnée sur les serveurs stor3 et stor4, ce qui n’a pas eu pour effet de libérer de l’espace disque sur les deux premiers serveurs. Il est donc nécessaire de répartir la volumétrie sur l’ensemble des bricks qui composent le volume :
root@stor2:~# gluster volume rebalance repl-vol start< volume rebalance: repl-vol: success: Rebalance on repl-vol has been started successfully. Use rebalance status command to check status of the rebalance process. ID: dffbed2e-3a0c-4d7d-9f43-9d978a546b04
Pour vérifier il suffit de lancer la même commande avec le paramètre status :
root@stor2:~# gluster volume rebalance repl-vol status Node Rebalanced-files size scanned failures skipped status run time in secs --------- ----------- ----------- ----------- ----------- ----------- ------------ -------------- localhost 5 0Bytes 10 0 0 completed 2.00 stor1 0 0Bytes 0 0 0 completed 1.00 stor3 0 0Bytes 2 0 0 completed 1.00 stor4 0 0Bytes 0 0 0 completed 1.00 volume rebalance: repl-vol: success
2.9 Les quotas
GlusterFS dispose d’un mécanisme permettant de définir des quotas au niveau dossier. Ils ne sont pas activés par défaut. Pour changer ce comportement :
root@stor2:~# gluster volume quota repl-vol enable volume quota : success
Nous allons appliquer une limite à 1Gio sur le sous-dossier subdir de notre volume. Ce dossier devra avoir été impérativement créé depuis le client glusterfs ajouté précédemment. Pour créer ce quota :
root@stor2:~# gluster volume quota repl-vol limit-usage /subdir 1GB volume quota : success
Si nous avions souhaité créer un quota au niveau du volume, il suffit d’indiquer / dans le chemin. Créons un fichier approchant le quota depuis notre client GlusterFS :
root@desktop:/data/subdir# dd if=/dev/zero of=/data/subdir/toto bs=1024 count=1024000 1024000+0 enregistrements lus 1024000+0 enregistrements écrits 1048576000 bytes (1,0 GB, 1000 MiB) copied, 223,044 s, 4,7 MB/s
Et voyons l’état du quota :
root@stor1:~# gluster volume quota repl-vol list Path Hard-limit Soft-limit Used Available Soft-limit exceeded? Hard-limit exceeded? ------------------------------------------------------------------------------------------------------------------------------- /subdir 1.0GB 80%(819.2MB) 1000.0MB 24.0MB Yes No
Reprenons notre commande précédente, en créant un fichier au nom différent, la création est bien interrompue sur le dépassement de quota hard :
root@desktop:/data# dd if=/dev/zero of=/data/subdir/tata bs=1024 count=1024000 dd: erreur d'écriture de '/data/subdir/tata': Débordement du quota d'espace disque dd: fermeture du fichier de sortie '/data/subdir/tata': Débordement du quota d'espace disque
Conclusion
Il est difficile d’être exhaustif sur un sujet aussi vaste. J’espère toutefois avoir aiguisé votre appétit sur GlusterFS et vous avoir donné l’envie de tester ce qui n’a pas été détaillé ici.
Niquel comme tuto, enfin un tuto vraiment complet.
Très intéressant…
Et côté perf qu’est-ce que ça donne svp ?
Très bonnes, mais c’est dépendant de beaucoup d’autres facteurs liés à l’infrastructure et au stockage utilisé.
Un très bon tutoriel pour découvrir les avantages de GlusterFS et faire ses premiers pas avec.
Super travail, merci beaucoup !
Merci!
Bonjour,
Très bon article sur Gluster.
Est ce que vous avez essayé les volumes de type « dispersed » ? Est ce que vous n’êtes pas partis dessus pour des raisons techniques ou est ce pour les besoins de l’article ?
Merci en tout cas pour ce bon tutoriel sur le sujet.
Cordialement,
Barth.
Bonjour Barthélémy,
Pour être honnête, je n’ai pas d’expérience sur les volumes dispersed donc j’ai préféré ne pas en parler.
Merci en tout cas et content que mon article ait pu t’être utile.
Julien
Bonjour Julien,
Super tuto…
As-tu migré une version 3.8/3.10 vers 5.2?
J’ai de nombreux problèmes de stabilité sur la v5.2, nombreux plantage côté mount.
Je cherche un consultant, as-tu des contacts? (Pays de Loire)
Merci d’avance,
PS : Divers problèmes : « rpc-transport/rdma.so no found », « 106228 – geo-replication no found », « 101032 – Path correspponding », « 101191 – event_dispatch_epoll_worker »
Bonjour Christophe,
Sur Nantes je te propose de contacter les entreprises membres d’Alliance Libre qui seront sans doute les plus à même de répondre à tes problématiques. Pas de soucis en v5 pour ma part.
Julien
Petite question, je fait du stripped replicated en test
Je souhaiterai savoir qui est replicated et qui est stripped afin de crée une carte avec les disque
car si je fait cela sur 4 disque, ça veut dire que je ne peux me permettre de perdre deux disque du même groupe sinon ça crash
Si quelqu’un à la réponse a serait cool
Merci
C’est l’ordre à la création qui est pris en compte mais un gluster volume info doit te donner une indication.
https://docs.gluster.org/en/latest/Administrator%20Guide/Setting%20Up%20Volumes/
Merci de ce tutorial. Toutefois j’espère ne pas avoir à m’y lancer seul 🙂 Je suis à Montpellier. Connaitriez-vous un pro dans mon coin qui pourrait mettre en place la réplication de mon serveur CENTOS dédié (aux US) sur une machine CENTOS de développement et archives chez moi. Ou est-ce que glusterfs n’est pas une bonne solution ?
Grand merci !
Bonjour,
Merci pour votre commentaire,, attention au délai de réplication entre les sites dans ce cas. Je crois que vous avez objectif libre dans votre région qui pourrait vous aider.
Julien
Bonjour,
Excellent article, merci beaucoup pour toutes ces informations, je me suis lancé dans glusterfs il y a peu car je voudrais mettre en place des services redondés en faisant mes tests avec 3 serveurs en mode replication et 2 clients j’ai remarqué que gluster-fuse a les mêmes propriétés que NFS j’arrive à monter ma partition sur les deux clients et à écrire en même temps ce qui est un gros avantage pas besoin d’utiliser NFS et c’est plus simple ainsi (l’intégration de nfs-ganesha n’a pas marché convenablement pour moi)
Par contre, sur mes 3 noeuds si je perds 2 noeuds sur 3 le montage n’est plus visible sur le client alors que mon troisième serveur est toujours up ce qui me semble un peu bizarre.
Une idée ?
Merci
@tahar, rien de plus normal. si tu as 3 noeuds le quorum (50% +1) et donc a 2 noeuds. Le but étant d’éviter une corruption des données (split-brain) . Si tu as une coupure X ou Y entre les serveurs, il faut un mécanisme pour savoir si une donnée a été légitimement modifié d’un cotés et pas de l’autre qu’elle est la bonne donnée à jour, donc y a un mécanisme de quorum et donc sur une base de 3 noeuds celui qui est tout seul à tord… cqfd
note: il faut toujours avoir un multiple impair de nœud, pour éviter le cas d’un 50-50 (2v2)
Je seconde ce que tu dis, rien n’empêche d’avoir un nombre pair de noeuds mais effectivement le seul moyen de se protéger d’un split brain c’est un nombre impair.
Avec un volume trois réplicas si tu perds deux noeuds, le quorum n’est pas atteint pour permettre le fonctionnement du volume.
Bonjour
Nous avons essayé d’utiliser Glusters pour stocker plusieurs Térabyte de données au travers d’une architecture avec un switch Cisco et différents serveurs (12) qui stockent nos données sur 6 Jbod Supermicro.
Notre problème est d’arriver à faire remonter touts les volumes sous Glusterfs, certains apparaissent d’autres non !
Nous recherchons un développeur pour nous aider à reprendre notre architecture et à faire évoluer notre installation.
Bonjour Leixx, je n’interviens pas en tant que freelance. Néanmoins, vous devriez trouver des intégrateurs ou des infogéreurs ne mesure de vous accompagner sur le sujet j’imagine?